
This blog provides you with the top 40 most frequently asked SQL Interview questions and answers as of right now, along with beginner-friendly explanations.
Table of Contents
- 1. What is SQL?
- 2. What is a database?
- 3. What distinguishes an RDBMS from a conventional DBMS?
- 4. Explain the different types of SQL commands.
- 5. How are MySQL and SQL different from one another?
- 6. What is a PRIMARY KEY constraint?
- 7. What is a FOREIGN KEY constraint?
- 8. What is a UNIQUE constraint?
- 9. What are SQL joins? What are the different types of joins?
- 10. What is a self join?
- 11. What is a cross join (Cartesian join)?
- 12. What distinguishes a HAVING clause from a WHERE clause?
- 13. What distinguishes a DELETE command from a TRUNCATE command?
- 14. What is a query?
- 15. What is a subquery?
- 16. What set operators are MINUS, INTERSECT, UNION, and UNION ALL?
- 17. What are Normalization and Denormalization?
- 18. What are scalar functions?
- 19. What are aggregate functions?
- 20. What is a stored procedure?
- 21. What is the SELECT statement?
- 22. What is an index?
- 23. Which SQL clauses are frequently used with SELECT queries?
- 24. What are character manipulation functions?
- 25. What is an SQL Server cursor? How do you use it?
- 26. What are the different types of indexes?
- 27. What distinguishes a non-clustered index from a clustered index?
- 28. What are ACID properties?
- 29. What is an schema?
- 30. What is an alias command in SQL?
- 31. How can I make empty tables that have the same layout as another table?
- 32. How can we choose unique records from a table?
- 33. What is the order by clause's default setting for data ordering? How might it be altered?
- 34. Which functions in SQL used for case manipulation?
- 35. What’s the standard syntax for SQL group functions?
- 36. What distinguishes the SQL datatypes CHAR and VARCHAR from one another?
- 37. What are user-defined functions in SQL? What are the various types?
- 38. What makes PL/SQL and SQL different from one another?
- 39. What are entities and relationships?
- 40. What is collation? What are the different collation sensitivity?
- 41. Syntax for most common SQL statements with Description
- Learn more about SQL and other topics
1. What is SQL?
In the 1970s IBM develop SQL, a non-procedural programming language, which Oracle eventually adopted. Nearly all relational databases utilize it for writing queries as well as for accessing, editing, and retrieving data.
SQL stands for Structured Query Language and mostly used for reading, writing and updating data into the relational databases.
2. What is a database?
An organized collection of digital data, or information, kept in a computer system is called a database. A database, as opposed to a spreadsheet, has the capacity to manage enormous amounts of data and permits numerous people to access the same database and conduct separate, secure searches.
3. What distinguishes an RDBMS from a conventional DBMS?
A database that uses a tabular schema to arrange several connected data items is called an RDBMS, or relational database management system. In addition to enabling limited access to the data inside, an RDBMS enables you to establish, create, and manage relational databases. An RDBMS, as previously mentioned, operates similarly to a DBMS, or database management system. DBMS data pieces, on the other hand, are not related to one another and are kept as files as opposed to tabular form.
4. Explain the different types of SQL commands.
There are six basic types of SQL commands
| Type | Description | Commands |
|---|---|---|
| Data Definition Language (DDL) | Utilized to create and restructure relational database objects, such as tables. | CREATE TABLE, ALTER TABLE, DROP TABLE, CREATE INDEX, ALTER INDEX, DROP INDEX, CREATE VIEW, DROP VIEW |
| Data Manipulation Language (DML) | Utilized to manipulate data within relational database. | INSERT, UPDATE, DELETE |
| Data Query Language (DQL) | DQL is used to execute queries within a relational database using this single command. | SELECT |
| Data Control Language (DCL) | Utilized in relational databases to manage data access. | ALTER PASSWORD, GRANT, REVOKE, CREATE SYNONYM |
| Data administration commands (DAC) | Used for auditing purposes or to analyze database processes. | START AUDIT, STOP AUDIT |
| Transactional control commands (TCL) | Utilized in relational databases for transaction management. | SET TRANSACTION, COMMIT, ROLLBACK, SAVEPOINT |
5. How are MySQL and SQL different from one another?
While MySQL is a well-known, open-source RDBMS, SQL is a programming language. While SQL is used to access, edit, update, and maintain data in MySQL, MySQL is used to store and organize data.
6. What is a PRIMARY KEY constraint?
A PRIMARY KEY constraint is a column or a group of columns used to uniquely identify each rows in a table. A primary key functions similarly to vehicle identification numbers (VINs), Social Security numbers issued by the federal government, and national government-issued identifying numbers.
Note: Each table may only have one PRIMARY KEY constraint. A PRIMARY KEY constraint requires that every column be specified as NOT NULL.
7. What is a FOREIGN KEY constraint?
A column or group of column in one table that references a primary key in another table is called a FOREIGN KEY. The foreign key-containing table is referred as the child table, and the main key-containing table is referred to as the parent table.
For instance, OwnerID is the primary key in the parent table below. The PRIMARY KEY uniquely identifies individual pet owners.
| OwnerID | LastName | FirstName | Address | PetCount |
|---|---|---|---|---|
| 2498 | Smith | Bonnie | 123 Mango Street | 2 |
| 2499 | Brown | Thomas | 456 Papaya Way | 0 |
| 2450 | Goes | Rosemary | 789 Apple Court | 1 |
For this child table, the PRIMARY KEY is PetID, and the OwnerID column is a FOREIGN KEYbecause it references the primary key of another table.
| PetID | PetName | Species | OwnerID |
|---|---|---|---|
| 1 | Whiskers | Cat | 2450 |
| 2 | Gilgamesh | Cockatiel | 2499 |
| 3 | Enkidu | Cockatiel | 2499 |
8. What is a UNIQUE constraint?
The UNIQUE constraint guarantees that each value in a column is distinct from all others, just like the PRIMARY KEY does. Tables, on the other hand, are not confined to one unique key constraint; instead, they can have numerous columns with unique constraints.
9. What are SQL joins? What are the different types of joins?
SQL’s JOIN clause connects rows of data from many tables together by utilizing related or shared columns. You can SELECT and return entries from several tables that have matching values for those related columns based on this relationship.
There are four different types of JOIN clauses available in SQL:
JOIN type | Description |
|---|---|
INNER JOIN | only returns entries from both tables where join column values matched |
LEFT JOIN | returns all entries in the left table in addition to entries with matching values in both tables using join column. |
RIGHT JOIN | returns all entries in the right table, in addition to entries with matching values in both tables using join column. |
FULL OUTER JOIN or FULL JOIN | returns all entries which matches in either the left or right tables using the join column. |
10. What is a self join?
Rows from two or more tables are combined using a JOIN clause based on a shared column. For comparisons within a table, a self join is just a conventional join except that the table is joined with itself.
Joining a table with itself means that each row in that is combined with itself and with every other row on the table.
11. What is a cross join (Cartesian join)?
Every row from the first table and every row from the second table are combined using a cross join in SQL. Because it yields the Cartesian product of the sets of rows from the joined tables, it is often referred to as the Cartesian join.
12. What distinguishes a HAVING clause from a WHERE clause?
The WHERE clause used to restrict rows from an SQL result set. It is considered to be the first condition, that returns only those rows that meet that condition. Where as HAVING clause is used to restrict groups of rows. It is considered as secondary conditions because it applies after WHERE and that can be applied to return only those groups that meet HAVING clause criteria.
13. What distinguishes a DELETE command from a TRUNCATE command?
| Differences | DELETE | TRUNCATE |
|---|---|---|
| Type | It is a DML (Data Manipulation Language) command | It is DDL (Data Definition Language) command |
| Function | Used to remove specific rows from table | Used to remove all rows from a table |
WHERE | Can contain WHERE clause to conditional delete rows | Cannot contain WHERE clause |
| Transaction logging | Row deletions are logged, hence slower | Deleted data are not logged, hence faster |
The TRUNCATE command runs faster as compared to DELETE because it is not generating any REDO log to recover data. Also unlike the DELETE command, data cannot be rolled back as no redo log generated for Truncate command.
14. What is a query?
Within the context of this article, a query is a series of instructions composed in a query language such as SQL that permits a user to get data stored in a database.
15. What is a subquery?
A query present inside in yet another query is considered as a subquery or nested query.
Subqueries come in two flavors: Correlated and Non-correlated.
- Correlated : subqueries make reference to a table column that the main query’s FROM keyword specifies.
- Non-correlated : The output of independent subqueries that are not correlated is used in place of the original query.
16. What set operators are MINUS, INTERSECT, UNION, and UNION ALL?
Combining the outcomes of two or more SELECT statements is known as the UNION operation. To obtain the UNION of sets A and B, for instance, all rows from both sets would be returned, with duplicate rows removed.
Similar to UNION, the UNION ALL action yields a result set but that contains duplicate rows.
Only the rows in both sets that have matching values are returned by the INTERSECT procedure, which combines the results of two SELECT operations.
The MINUS operation removes the common rows from the result of two SELECT statements and returns rows that only belong to the first set of the result.
17. What are Normalization and Denormalization?
The term “normalization” describes techniques used to eliminate redundancies and inconsistent data in databases.
The term “denormalization” describes techniques for enhancing query performance.
Normalization increases the number of tables in a database while denormalization decreases it.
18. What are scalar functions?
The user defines functions, which take an input value and always return a single value (such as an int, char, float, etc.) is considered as scalar functions.
Common SQL scalar functions:
CONCATcombine or concatenates two or more character strings.LENcalculates the total length of a given column.ROUNDrounds the integer value for a numeric field.NOWreturns the current date and time.RANDgenerates a group of random numbers of a provided length.
19. What are aggregate functions?
Aggregate functions also commonly referred as group functions are applied to a group of rows to generate and return a single value for each groups.
Some of the common SQL aggregate functions are:
AVGdetermines the average or mean with in a group.COUNTdetermines the number of rows in group, including rows withNULLvalues.MINandMAXreturns the smallest and largest value with in a group, respectively.SUMreturns the total of all non null values with in a group.STDDEVdetermines the standard deviation.VARIANCEdetermines the variance
20. What is a stored procedure?
The group of related code that can be clubbed with in an object is considered as Stored procedure. You can preserve the same SQL query as a stored procedure and call on it as needed to run it, saving you the trouble of writing it down repeatedly.
Store an SQL query:
CREATE PROCEDURE procedure_name
AS
sql_statements
GO;Execute a stored procedure:
EXEC/Call procedure_name;21. What is the SELECT statement?
The SELECT statement is a DQL (Data Query Language) statement and is used in SQL queries to extract particular attributes or data components from a table and return them in a result set.
General SELECT syntax:
SELECT column_1, column_2, ...
FROM table_name;To select all data elements from a table, use
SELECT * FROM table_name;22. What is an index?
An Index is a database object used to faster access to particular records or data point. The database search engine uses a SQL index, which is a lookup table, to locate and retrieve data fast. While an index can speed up the creation of SELECT and WHERE clauses, it can also slow down the use of INSERT and UPDATE commands.
To create an index:
CREATE INDEX index_name ON table_name;23. Which SQL clauses are frequently used with SELECT queries?
The SELECT statement mainly contains three clauses out of three, two are mandatory:
SELECTspecifies the table columns to retrieve, it is a mandatoryFROMspecifies the tables to access, it is a mandatoryWHEREclause specifies which rows in theFROMtables to retrieve, is an optional clause
Other clauses that we can utilise in SELECT are
- GROUP BY: When using aggregate functions, the GROUP BY clause is utilized to group the result set based on predetermined columns.
HAVING: Used to restrict groups similar to Where clause which restricts rowsORDER BY: utilises to sort the result in particular order. Can sort result in ascending (ASC) the default or descending (DESC) order according to a specified column.
Below is the general order for a SELECT statement
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s);24. What are character manipulation functions?
Functions using with character strings can be edited, changed, or rearranged are considered as character manipulation functions.
For instance, you can use a SELECT query to provide two character strings into the CONCAT function in order to concatenate them.
25. What is an SQL Server cursor? How do you use it?
Cursors are memory area in database that helps you navigate across multiple records by processing result sets one row at a time. Cursors can be used to highlight specific rows within a collection of rows.
You can DECLARE a cursor after any variable declaration.
DECLARE variable_name CHAR(20)
DECLARE your_cursor_name CURSOR FOR
SELECT column_1, column_2
FROM your_table_name26. What are the different types of indexes?
- Clustered indexes: The primary body of data is clustered with the clustered indexes. Based on the table’s key values, a clustered index progressively sorts and saves rows of data in a table or view to correspond with the index’s order. Each table may only have a single clustered index.
- Non-clustered indexes: Non-clustered indexes cannot be used to store or sort data in the main table; instead, they are independent of it. A non-clustered index’s order is determined by its key values rather than by the table.
- Column store indexes: A common type of index that effectively stores data in a column-based structure as opposed to a row-oriented one is the column store index.
- Filtered indexes: One way to index a portion of the rows in a table is to use filtered indexes.
- Hash indexes: The hash function F(K, N), where K is the critical number and N is the number of slots holding a pointer and row, is used by hash indexes, which are arrays.
- Unique indexes:To ensure that there are no duplicate values in the index key, unique indexes give distinct values to each row of data.
27. What distinguishes a non-clustered index from a clustered index?
In a clustered index, the rows are arranged in the same order as they are in the database. One clustered index per table is allowed at a time.
Similar to a clustered index, a non-clustered index generates a distinct item within the database that references the original table, but it operates more slowly. A table can contains more than one non-clustered index.
28. What are ACID properties?
The properties that are required to be adhered to in order for transactions in a database management system to stay consistent are known as the ACID properties.
- Atomicity: Either everything happens at once, or nothing happens at all.
- Consistency: Before and after a transaction, a database must to be consistent.
- Isolation: Individual transactions can operate independently and concurrently with one another and happen on their own.
- Durability: In order for transaction records to survive a system failure, database updates must be written to and kept on disk.
29. What is an schema?
A schema is a collection of related database objects. It is also considered as an abstract representation of logically structured data in database. A database user referred to as the schema owner defines database schemas in SQL at the logical level.
30. What is an alias command in SQL?
The alias (AS) command makes columns or tables easier to read by giving them temporary names for the duration of a query.
31. How can I make empty tables that have the same layout as another table?
The below SQL command can be used to create an empty table based on the source table.
CREATE TABLE <your_new_table> LIKE <data_source_table>; #some database supports that but not all
#Other way
CREATE TABLE <your_new_table> as SELECT * FROM <data_source_table> WHERE <1=2>;32. How can we choose unique records from a table?
Using DISTINCT clause in SELECT statement we can returns only unique rows from a table.
33. What is the order by clause’s default setting for data ordering? How might it be altered?
Data are arranged in ascending (ASC) order by default. Using the descending (DESC) keyword with the ORDER BY clause, you can alter the order as follows:
SELECT *
FROM your_new_table
ORDER BY column_name DESC;34. Which functions in SQL used for case manipulation?
LOWER() orLCASE(): A given character string can be fed into this function to convert it to lower case.UPPER() orUCASE(): A given character string can be fed into this function to convert it to upper case.
35. What’s the standard syntax for SQL group functions?
The general syntax is:
SELECT column_name, group_function(column_name)
FROM table_name
WHERE condition
GROUP BY column_name
ORDER BY column_name36. What distinguishes the SQL datatypes CHAR and VARCHAR from one another?
Character strings with a defined length are stored in the character, or CHAR, datatype. Where as variable character or VARCHAR datatype stores variable length character strings.
CHAR has better performance than VARCHAR, but VARCHAR can be useful for anticipating data values without a set length.
37. What are user-defined functions in SQL? What are the various types?
There are two types of functions in SQL:
- System Defined Functions (SDF) and
- User-Defined Functions (UDF)
User-Defined Functions (UDFs) are function that are declared and defined by a user and are similar to functions found in many programming languages. UDFs can accept parameters, perform complex calculations, and return their results.
There are three types of UDFs that a user can create:
- Scalar Functions: The only value that a scalar function can return is a single value, and it can return any sort of data except text, images, cursors, and timestamps.
- Inline Table-Valued Functions: A table of values is the output of inline table-valued functions. The return statement determines the structure of the table that the function returns and can only prepare one SELECT statement.
- Multi-Statement Table-Valued Functions: These functions return a table of values as well, but they can also contain several statements and the user defines the table’s structure.
38. What makes PL/SQL and SQL different from one another?
SQL communicates with the database server directly and is not procedural. It’s easy to learn and use, but if you need to solve more complicated SQL problems and are willing to learn some more complex concepts, then PL/SQL can be a powerful tool.
PL/SQL is a procedural language that doesn’t interact directly with the database server but offers a faster processing speed and an expanded range of supported features. With PL/SQL, you can use SQL for anything you need to do and more
PL/SQL:
- is mostly utilized to write functions, packages, procedures, program blocks, and more based on business logic.
- Supports for variables, conditional statements, and loops.
- Supports error and exception handling.
39. What are entities and relationships?
An entity is a physical real world object that can be recognized by a group of similar characteristics. A zoo database may contain information about zookeepers, veterinarians, various public outreach programs, or animal species.
Links between things that are connected to one another are called relationships.
The logical relationship between entities creates a database.
40. What is collation? What are the different collation sensitivity?
Collation is a configuration option that describes the comparison and sorting of data in a database. To ascertain which character sequence should be utilized to sort the character data, various collation rules can be set up.
Collation sensitivity is a useful tool for controlling how certain characters are handled.
- Accent sensitivity: makes a distinction between a and á.
- Case sensitivity: makes a distinction between A and a.
- Kana sensitivity: makes a distinction between Japanese Hiragana and Katakana.
- Width sensitivity: characters with varying widths (single-byte and double-byte) are handled differently by width sensitivity.
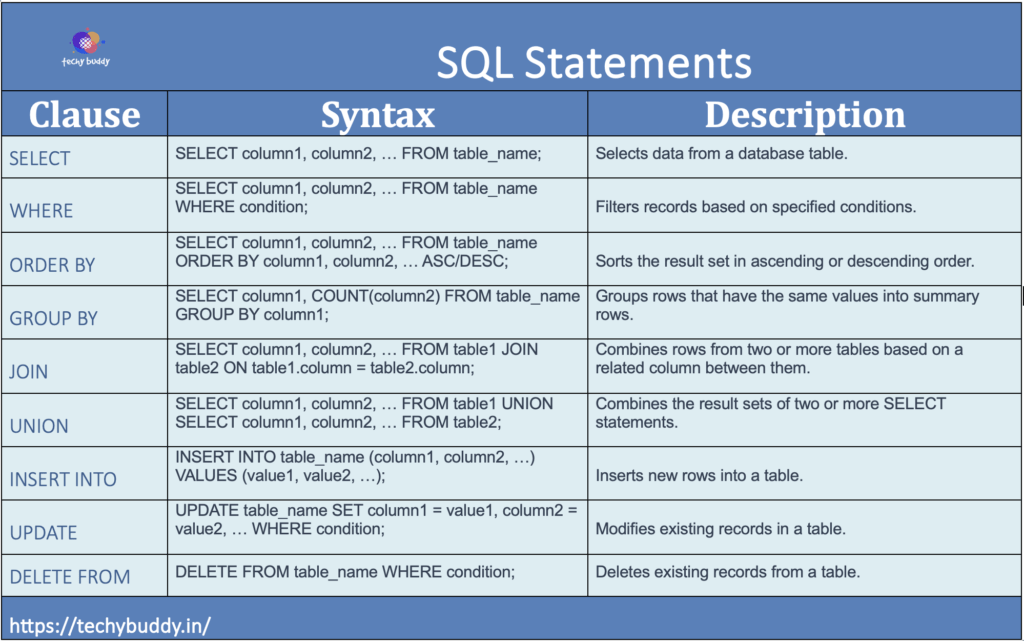
41. Syntax for most common SQL statements with Description
Learn more about SQL and other topics
- Oracle Interview Questions: Must Know Before Your Big Day
- What Are the Most Common SQL Tricks Everyone Should Know?
- Are You Good Enough in PLSQL? Test your knowledge right now
- NoSQL Vs SQL Databases: An Ultimate Guide To Choose
- Learn SQL by Oracle
- What is SQL by AWS