
One can choose from a wide variety of machine learning algorithms. Each has benefits and drawbacks of its own. Below are some most popular machine learning algorithms along with their pros and cons.
Table of Content
Machine Learning Algorithms
The below list contains most commonly used machine learning algorithms which can be applied to almost any data problem now a days:
- Linear Regression
- Logistic Regression
- kNN – K Nearest Neighbour
- Decision Tree
- K-Means
- PCA – Principal Component Analysis
- SVM – Support Vector Machine
- Naive Bayes
- ANN – Artificial neural network
- Adaboost
- Random Forest
1. Linear Regression
Linear regression is an algorithm that establishes a linear relationship between an independent variable and a dependent variable. Its purpose is to predict future outcomes. This statistical method is widely used in data science and machine learning for predictive analysis.
The linear regression algorithm models the linear association between a dependent variable (often denoted as y) and one or more independent variables (usually denoted as x). Because it captures this linear relationship, it enables us to understand how the dependent variable’s value changes based on variations in the independent variable(s).

Pros
- Simple to implement and efficient to train
- Over-fitting can be reduced by regularization
- Have good performance specially if dataset can separate linearly
Cons
- Assumes that the dataset is independent which is rare is real life
- Very prone to noise and over-fitting
- Sensitive to outliers
2. Logistic Regression
Logistic regression is a statistical technique employed in machine learning to construct models when the dependent variable is binary (i.e., it has two possible outcomes). This process helps to describe the data and create the relationship between a dependent variable and one or more independent variables.
With logistic regression, the result of a categorical dependent variable is predicted. This means that the result must be a categorical or discrete value, such as “Yes” or “No,” “0” or “1,” or “true” or “false.” However, instead of providing an exact value of 0 or 1, logistic regression produces probabilistic values that fall between 0 and 1. These values indicate the likelihood of a particular event.

Pros
- It is less susceptible to overfitting, although it can still overfit in high-dimensional datasets
- It performs efficiently when dealing with datasets where features are linearly separable.
- Implementation is straightforward, and it is an efficient training method.
Cons
- Logistic regression should not be used when the number of observations (data points) is smaller than the number of features (predictor variables). Having too few data points relative to the number of features can lead to unreliable results
- Logistic regression considers that the relationship is linear between the independent variables and the log of the dependent variable. However, in real-world scenarios, relationships are often more complex.
- Logistic regression is suitable for predicting discrete outcomes, such as binary classification (e.g., yes/no, spam/not spam). It does not directly handle continuous predictions.
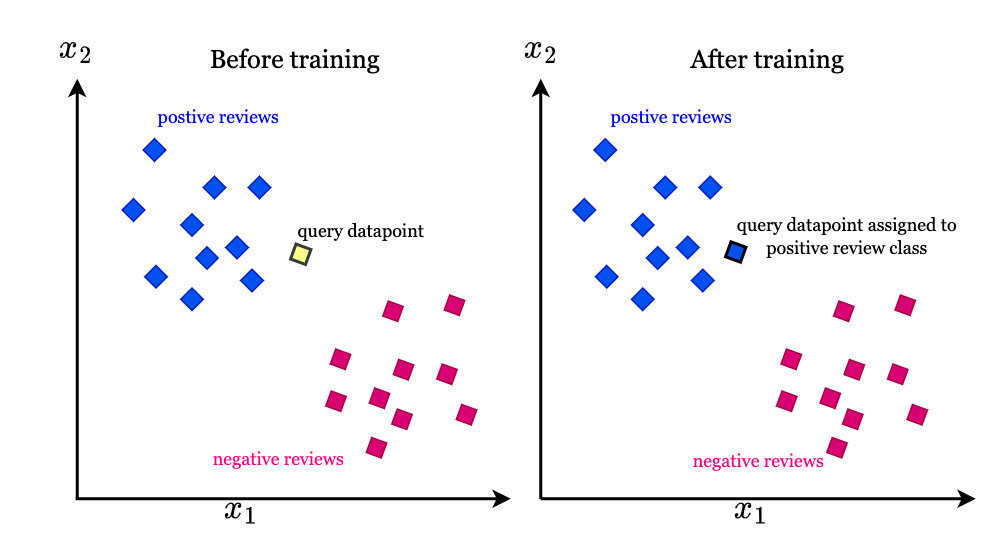
3. K Nearest Neighbour
The k-nearest neighbors algorithm, also most commonly referred as KNN or k-NN, is a non-parametric, supervised learning algorithms, which uses distance or proximity to classify a data point to which grouping this belongs to.
KNN is often referred to as a “lazy learner” because it doesn’t immediately learn from the training data. Instead, it stores the entire dataset and performs actions on it during classification. This contrasts with eager learners that build explicit models during training. KNN is non-parametric, meaning it doesn’t assume any specific distribution for the underlying data. Unlike algorithms like Gaussian Mixture Models (GMM), which assume a Gaussian distribution, KNN remains flexible and adaptable.
Pros
- It can make output or predictions without any training
- Time complexity in O(n)
- It can be utilised for both classification and regression problems
Cons
- Not perfom well with huge dataset
- Results may vary due to its sensitivity to outliers, noisy data or with missing values
- Require feature scaling
- It required to select the correct K value
4. Decision Tree
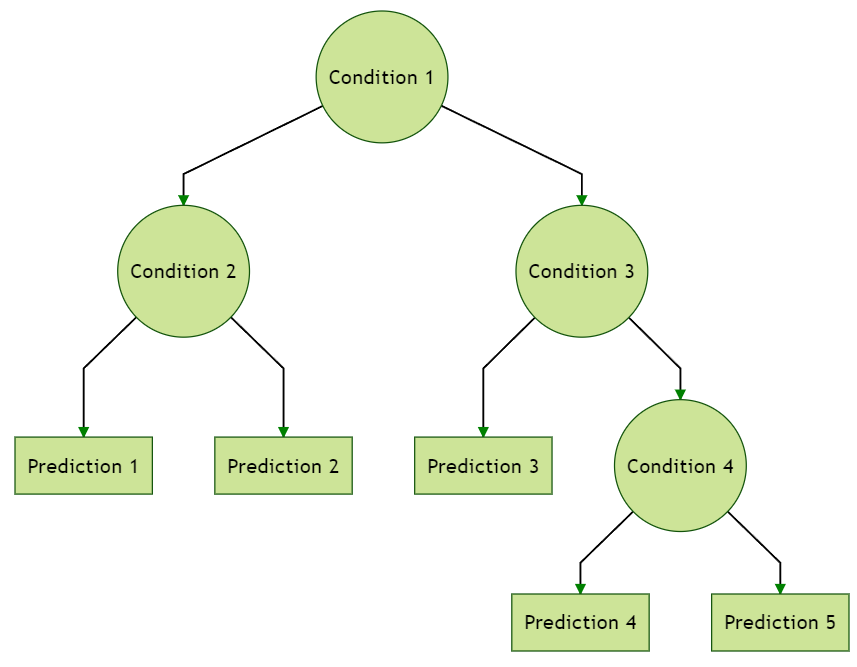
A decision tree is another supervised learning algorithm that is mostly utilised to solve both type of problems – classification and regression. It follows a hierarchical, tree-like structure comprising the following components:
- Root Node: The topmost node represents the complete dataset and serves as the starting point for the decision-making process.
- Internal Nodes: These nodes symbolize choices related to input features. Each internal node connects to leaf nodes or other internal nodes through branches.
- Leaf (Terminal) Nodes: These nodes lack child nodes and provide the final output—either a class label (for classification) or a numerical value (for regression).
It is having two nodes, which are the Decision Node and Leaf Node. Decision nodes are utilised to make decision and can have multiple branches, whereas Leaf nodes are the yield of those decisions and do not contain any other branches.
Pros
- Can used to solve non-linear problems
- Having excellent accuracy even with high-dimensional data
- Easy to explain and interpret
Cons
- Over-fitting might be resolved by random forest
- A little change in the data set can make a huge change in the structure of already optimized decision tree
- Calculations can get exceptionally complex
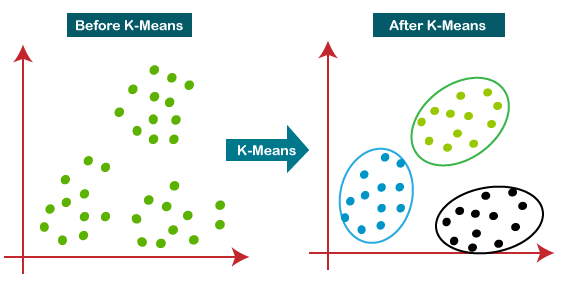
5. K Means
K-means is a centroid-based algorithm. Also known as a distance-based algorithm, where we calculate the distances to assign a point to a cluster. K-means is an iterative algorithm that splits a dataset into clusters which are non-overlapping subgroups.
K-Means clustering is an unsupervised learning algorithm, which means it can be utilised for the clustering on un-labeled data set. It create grouping of data points also known as clusters that are sharing similarities and are different from the data points belongs to another group or cluster.
Pros
- Easy algorithm to implement
- Can scales to huge data sets
- Guarantees convergence
- Can be easily adjusted to new data sets
- Generalizes to clusters of various shapes and sizes
Cons
- Sensitive to the outliers
- Selecting the value of ‘k’ manually is not easy
- Dependent on initial values
- Scalability is inversely proportion to dimensions and it decreases when the number of dimensions increases
6. Principal Component Analysis
Principal Component Analysis is another unsupervised learning algorithm that is mostly utilized for the dimensionality reduction in machine learning. PCA employs orthogonal transformation that converts the set of observations from possibly correlated features into a new set of linearly uncorrelated features and that new transformed features are called the Principal Components.
It is among the most widely used instruments for exploratory data analysis and predictive modeling, or EDA. PCA is a statistical method that aims to identify significant patterns within a given dataset by reducing the variances of the original features.

Pros
- Reduce related features
- Improve performance
- Reduce over-fitting
Cons
- Principal components are less interpretable
- Information loosing: decreasing components result in loosing information
- PCA required standardize data set before implementing it
7. Support Vector Machine
Support Vector Machine or also most commonly known as SVM is highly used Supervised Learning algorithms, which can be easily utilised in both type of classification and regression tasks. But it’s mostly applied to machine learning classification challenges.
SVM algorithm utilised a concept of hyperplane which is a boundary to separate n-dimensional space. SVM strive to create the best possible hyperplane or decision boundary within the data set to divide them into different classes. This decision boundary is used to classify new data points in different classes.

Pros
- Perform well with high dimensional data
- Generally work well on small dataset
- Can utilised to solve non-linear problems
Cons
- Inefficient if applying on huge data
- Requires choosing the correct kernel
8. Naive Bayes
The Naïve Bayes method utilizes the Bayes theorem as a supervised learning strategy to tackle classification problems.
As a probabilistic classifier, it makes predictions based on the likelihood of an object belonging to a particular class. Notable applications of the Naïve Bayes Algorithm include spam filtering, sentiment analysis, and article classification.
The formula for Bayes’ theorem is
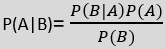
Pros
- Training period is less
- Better suited for categorical inputs
- Easy to implement
Cons
- It assumes all of its features are to be independent but in practice, it is uncommon for all features to be truly independent.
- Zero frequency
- Estimations can be wrong in some cases
9 . ANN
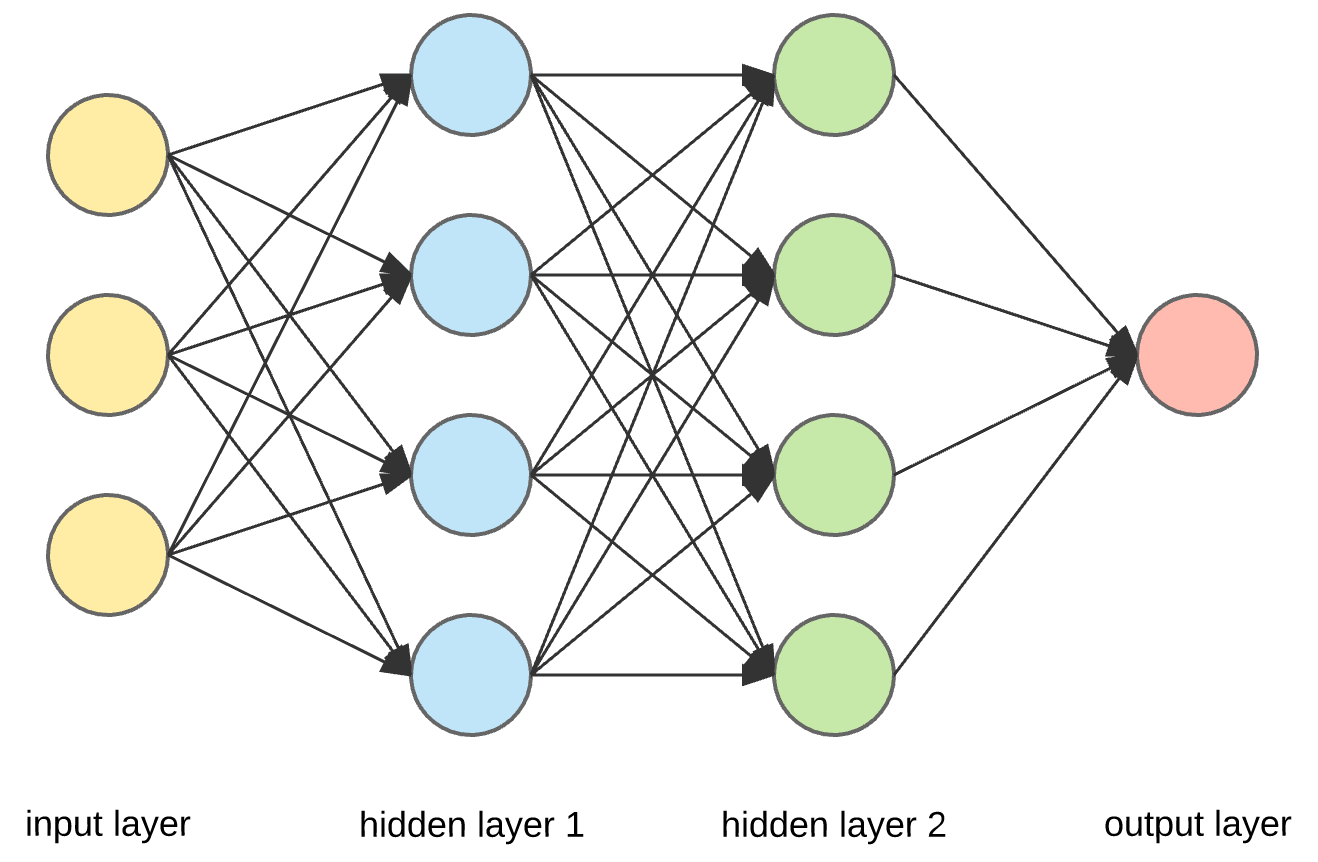
Artificial Neural Networks (ANNs) are computational models inspired by the intricate processes of the human brain. These networks utilize mathematical computations to mimic brain functions. Recent breakthroughs in artificial intelligence have been closely tied to ANNs, particularly in fields such as image recognition, voice processing, and robotics. The versatility of ANNs continues to drive innovation and progress in these domains.
Artificial Neural Networks (ANNs) strive to emulate the neural networks discovered in the human brain. . The learning algorithms used for training ANNs often employ mathematical techniques derived from the gradient descent method. Additionally, feature-extracting ANNs transform high-dimensional input data sets into two-dimensional representations.
Pros
- Have fault tolerance
- Can learn and model complex relationships including non-linear relationships as well
- Can generalise on unseen data
Cons
- Long training time
- Non-guaranteed convergence
- Black box, hard to explain solution
- Hardware dependence
- Requires user’s ability to translate the problem
10. Adaboost
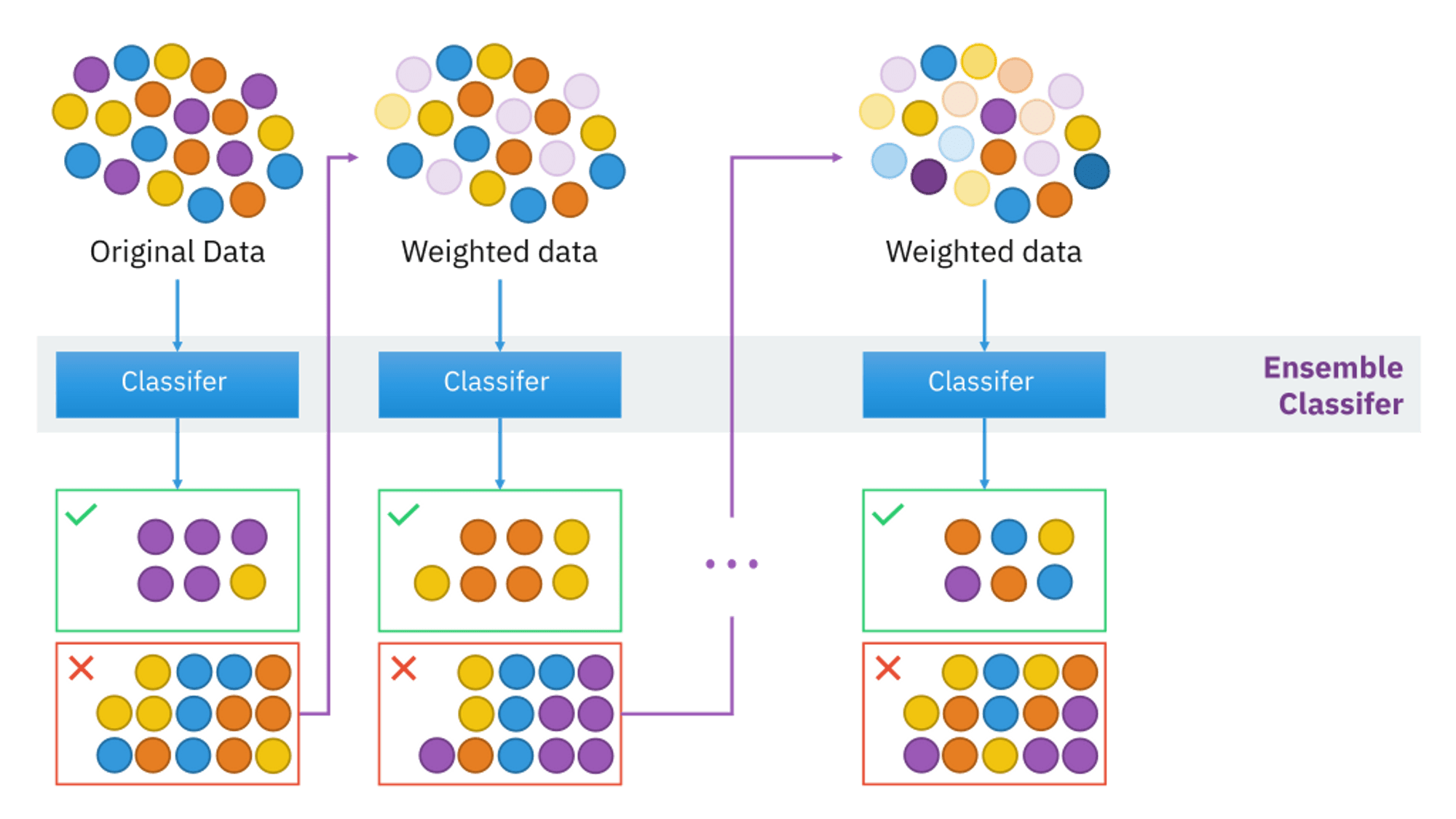
AdaBoost, also known as Adaptive Boosting, represents an ensemble machine learning algorithm applicable to a diverse range of classification and regression tasks. As a supervised learning technique, AdaBoost combines several weak or base learners (such as decision trees) to create a robust and powerful model for data classification.
Pros
- Relatively robust to over-fitting
- High accuracy
- Easy to understand and to visualise
Cons
- Sensitive to noisy data
- Affected by outliers
- Not optimised for speed
11. Random Forest
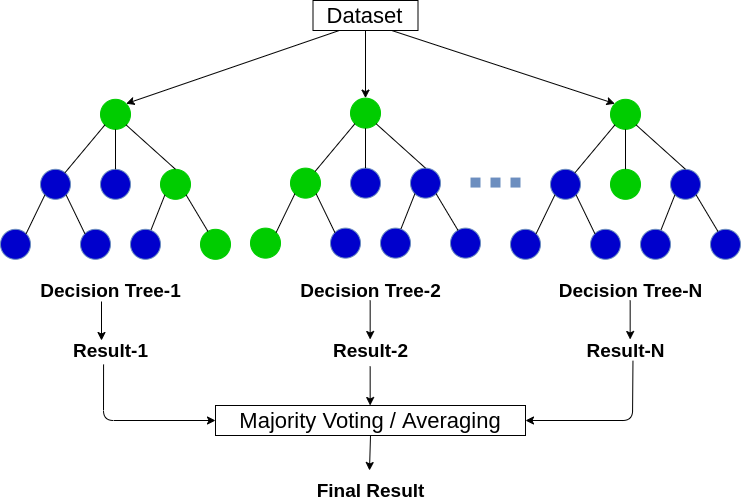
Random Forest is a widely used machine learning algorithm that aggregates the predictions from multiple decision trees to produce a final output. It leverages the concept of ensemble learning, where several individual classifiers (specifically, decision trees) collaborate to address intricate problems and enhance the overall performance of the model.
‘n’ the context of Random Forest, it serves a dual purpose: classification and regression tasks. When dealing with classification, the final output is determined by the class chosen by the majority of trees. In contrast, for regression, the predictions from individual trees are averaged to arrive at the final result.
Pros
- Robust to noisy data and outliers
- High accuracy
- Feature importance: Helps to identify which features contributes significantly
- Effectively handling of high dimensional data
- Versatility: Can apply to both classification and regression problems
Cons
- Complexity and Computational Time
- Not easy to understand and to visualise
- High memory usage
- Bias from subset sampling
Learn more about machine learning and other topics
- Machine Learning: A Quick Refresher & Ultimate Cheat Sheet
- Machine Learning Algorithms by IBM
- The Ultimate Cheat Sheet for Deep Learning
- Cloud Load Balancing: How To Choose?
- AWS Redshift Vs Snowflake: How To Choose?
- NoSQL Vs SQL Databases: An Ultimate Guide To Choose